
요즘 기업 면접을 본다고 매우 정신이 없다. IntellIJ도 정말 오랜만에 켜보는 것 같다.
이번 정리글은 면접 과정에서 질문에서 준비할려고 했지만 준비하지 못한 질문을 받아서 해당 글이 잘 정리되어있는 원문을 번역해보려고 한다.
Raw SQL vs Query Builder vs ORM
How to talk with your relational database
Raw SQL vs Query Builder vs ORM
How do you talk with your relational database?
levelup.gitconnected.com
데이터베이스는 거의 모든 웹 애플리케이션에 대한 상태 저장의 핵심이다. 이러한 이유로 데이터베이스와의 상호 작용을 관리하는 것은 응용 프로그램이 계속 실행되도록하는 데 중요하다. 대부분의 관계형 데이터베이스와 상호 작용을 하는 방법은 SQL(구조화된 질의 언어) 이다. SQL은 실제 데이터베이스 시스템이나 해당 데이터베이스를 사용하는 클라이언트를 전환하는 것을 아주 간단하게 만든다. 모든곳에는 SQL이 있다. 데이터베이스 드라이버가 필요하고, 그 다음 일반적인 CRUD 상호작용을 수행할 수 있다. (데이터 생성, 읽고, 업데이트하고, 삭제)
이 문서를 읽으면 Raw SQL, Query Builder 그리고 ORM을 사용해야 하는 시기를 알 수 있다. 또한 파이썬에서 각 항목을 사용하는 방법도 알 수 있다.
이 문서의 모든 코드는 실행 가능하다. 데이터베이스를 초기화하고 환경 변수만 추가하면 된다. 환경 변수를 설정하기 위해 direnv를 한다.
Raw SQL
Native SQL 이라고도 하는 Raw SQL은 가장 기본적이고 가장 낮은 수준의 데이터베이스 상호 작용 형태입니다. 데이터베이스언어로 수행할 작업을 데이터베이스에 알려줍니다. 대부분의 개발자는 SQL의 기본 사항을 알고 있어야 한다. 즉, 테이블 및 뷰를 생성하는 방법, 데이터를 선택하고 조인하는 방법, 데이터를 업데이트 및 삭제하는 방법을 의미한다. 저장 프로시저, T-SQ, PL-SQL, 인덱스와 인덱스의 효과에 대한 심층적인 지식 등 더 복잡한 경우 지식인을 찾기가 훨씬 더 어려워질 것이다. SQL은 많은 개발자들이 생각하는 것보다 훨씬 강력하다. 예를 들어 SQL로 Mandelbrot 집합을 만드는 방법을 알지 못한다.
원시 SQL 문의 문제를 설명하려면 책 포털의 예를 들어 본다. 사용자는 책에 대한 데이터(예: 제목, 원본 언어 및 작성자)를 볼 수 있다.
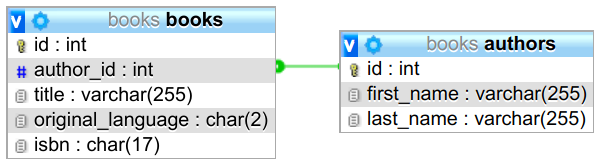
Every book has exactly one author, but every author might have an arbitrary number of books.
저자 페이지의 경우 authors.id이 제공되며 해당 작가가 작성한 모든 책 목록을 보고 싶다면;
pstmt = con.prepareStatement("SELECT * FROM books WHERE author_id = %author_id");
ResultSet rs = pstmt.executeQuery();
while (rs.next())
{
System.out.println("ID = " + rs.getInt(1) + ", NAME = " + rs.getString(2));
}긍정적인 측면에서는 Raw SQL에서 어떤 일이 발생하는지 매우 명확합니다. Python과 SQL에 대한 지식만 있으면 됩니다. 타사 소프트웨어에 대해 깊이 생각할 필요가 없습니다.
그러나 Raw SQL을 사용하는 것과 관련하여 알아야 할 6가지 부정적인 측면이 있습니다.
Problem 1: SQL Injections
SQL 주입은 공격자가 예기치 않은 방법으로 채울 수 있는 SQL 쿼리에 자리 표시자가 있는 서비스에 대한 공격입니다. 예를 들어:
sql = "SELECT user_id FROM users WHERE name='{name}' AND pw='{pw}';"이러한 접근 방식을 사용할 경우 공격자는 pw에는 ' OR name='admin' 및 '1'='1을 입력하고 이름에 대해서는 비워 둘 수 있습니다. 이렇게 하면 쿼리가 발생합니다.
SELECT user_id
FROM users
WHERE name='' AND pw=''
OR name='admin' AND '1'='1'이렇게 하면 기본적으로 사용자가 관리자로 로그인한 응용 프로그램을 알 수 있습니다.
물론 인용구를 피하고 사용자 입력에 직접 붙여넣지 않는 것이 좋습니다. 하지만 개발자들은 실수를 한다. Raw SQL 쿼리를 사용하면 이러한 실수를 쉽게 할 수 있습니다.
Problem 2: Typos in SQL Commands
문자열 프로그래밍의 첫 번째 명백한 문제는 하위 언어의 오타가 편집자에 의해 감지될 수 없다는 것이다.
sql = "SELECT * FROM books;"Problem 3: Missing Editor Support
이 문제는 상당히 멍청하지만, 여전히 많은 언어/에디터들에게는 미해결 문제입니다. 개발자가 SQL을 언어 내에서 문자열로만 작성할 때 에디터는 이 문자열을 구문 분석해야 한다는 것을 어떻게 알 수 있는가? 에디터가 구문 강조 표시 및 자동 완성을 원하는지 어떻게 알 수 있습니까?
ㅠㅠ 대부분은 지원안하지만... JDBC에선 지원을 해줬던걸로 기억합니다 🥲
원시 쿼리가 정말로 필요하지만 구문 강조 표시를 원하는 경우 각 쿼리를 고유한 query.sql 파일에 저장할 수 있습니다. 이렇게 하면 에디터는 SQL 구문 강조 표시를 사용할 수 있습니다.
Problem 4: Typos in Table or Column Names
sql = "SELECT * from boks;"이러한 오류들은 찾기가 훨씬 어렵다. 이제 확인하는 코드는 SQL의 작동 방식뿐만 아니라 데이터도 알아야 합니다. 정확한 데이터베이스 스키마여야 한다.
Problem 5: Change management
데이터베이스는 시간에 따라 변경됩니다. Raw SQL의 경우 일반적으로 이에 대한 지원을 받을 수 없습니다. 스키마와 모든 쿼리를 직접 마이그레이션해야 합니다. ㅜㅠㅠ
Problem 6: Query Extension
분석 쿼리가 있는 경우 약간의 수정을 적용할 수 있으면 좋습니다. 예를 들어, 버튼을 클릭한 사용자 수를 알 수 있는 데이터 추적을 상상해 보십시오. 이에 대한 "기본 쿼리"가 있을 수 있습니다. 사용 사례에 따라 특정 기간 동안 필터링하거나 사용자의 특성을 필터링할 수 있습니다. Raw SQL이 있을 때 쿼리를 확장할 수 있지만 번거롭습니다. 원래 쿼리를 건들고 placeholder를 추가해야 합니다.
Query Builder
SQL 쿼리를 작성하기 위해 사용하는 프로그래밍 언어로 작성되고 네이티브 클래스 및 함수를 사용하는 라이브러리를 Query Builder라고 합니다. Query Builder는 일반적으로 인터페이스가 유창합니다. 즉, 쿼리는 method chain을 사용하는 객체 지향 인터페이스에 의해 작성됩니다.
query = Query.from_(books) \
.select("*") \
.where(books.author_id == aid);query builders라고도 불리는 그래픽 도구도 있지만, 이 글에서 의미하는 것은 아닙니다.
JavaScript는 Knex, PHP는 Doctrine을, JAVA에는 QueryDSL과 JOOQ가 있다.
Pypika는 Python의 쿼리 작성기의 예입니다. 위의 예제 쿼리는 다음과 같이 작성 및 실행할 수 있습니다.
# Core Library modules
from typing import List
# Third party modules
import pymysql.cursors
from pypika import Query, Table
# First party modules
from raw_sql import db_connection
@db_connection
def get_titles_by_author(con, author_id: int) -> List[str]:
books = Table()
q = Query.from_(books).select("*").where(books.author_id == author_id)
cur = con.cursor(pymysql.cursors.DictCursor)
query = q.get_sql(quote_char=None)
cur.execute(query)
titles = [row["title"] for row in cur.fetchall()]
return titles
if __name__ == "__main__":
print(get_titles_by_author(1))결과 쿼리는 원시 코드와 동일합니다. 그것은 단지 다른 방식으로 지어졌을 뿐입니다. 이는 데이터베이스 성능이 여전히 동일함을 의미합니다. 또한 쿼리 작성은 복잡한 작업이 아니므로 애플리케이션 성능은 전체적으로 동일하게 유지되어야 합니다.
또한 연결 처리가 이전과 동일하게 수행되었음을 확인할 수 있습니다. raw SQL 예제에 비해 코드의 총 줄이 3줄 늘어났습니다. 그러나 쿼리를 확장 및 재사용하기가 더 쉽습니다. 예를 들어, 복잡한 조인 집합과 많은 WHERE 문이 있다고 가정해 볼 수 있습니다. 일반 SQL 쿼리를 사용하면 옵션 추가를 할 수 있습니다. Query Builder를 사용하면 쿼리를 더 쉽게 확장하고 재사용할 수 있습니다. 재사용하기 위해 쿼리 q를 어딘가에 노출시킬 수 있습니다.
쿼리 작성기는 위의 예에서 제공된 부품인 .select, .from_에서 오타를 방지합니다. 열 이름은 여전히 문자열일 뿐이므로, 열 이름에는 도움이 되지 않습니다. 즉, Query Builder는 문제 1과 2를 해결하고 문제 3을 해결하지만 여전히 문제 4와 5를 가지고 있습니다.
ORM: Object-Relational Mapper
ORM은 각 데이터베이스 테이블에 대해 개체(object)를 만듭니다. 이렇게 하면 언어 고유의 표현이 존재하므로 자동 완성 및 구문 강조 작업과 같은 모든 언어 생태계의 기능이 제공됩니다.
ORM은 Java는 Hibernate, PHP는 Eloquent, Ruby는 activerecord, JavaScript는 squalize 및 TypeORM, Python은 SQLLCemy 등 다양한 언어에서 매우 인기가 있습니다.
예제는 생략하겠습니다.
ORM의 멋진 점은 때때로 변화에 도움이 된다는 것입니다. 파이썬에는 마지막으로 알고 있는 데이터베이스 상태와 비교하여 모델이 변경된 시점을 자동으로 감지할 수 있는 Alembic이 있습니다. 그러면 Alembic이 스키마 마이그레이션 파일을 작성할 수 있습니다.
데이터베이스의 테이블을 나타내는 개체(object)가 있도록 코드 내에서 데이터베이스를 나타내는 초기 작업이 필요합니다. 초기 작업 후에는 데이터베이스가 query builder 코드 기반과 동기화되었는지 확인해야 합니다. 이러한 노력으로 새로운 쿼리를 작성하기만 하면 개발 속도가 빨라집니다. 구문 강조 표시 및 자동 형식 지정도 사용할 수 있으므로 쿼리를 보다 쉽게 읽을 수 있어 유지 관리를 줄일 수 있습니다.
Over-fetching Problem
ORM으로 쿼리를 실행할 때 필요한 것보다 더 많은 쿼리가 발생할 수 있습니다. 예를 들어, 위에서 책 조회에 ORM을 직접 사용하려는 경우 다음과 같이 외래 키를 정의합니다.
@Entity
class Author {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
private String firstName;
private String lastName;
@OneToMany(mappedBy = "author", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Book> books = new ArrayList<>();
}
// =====
@Entity
class Book {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
private String title;
private String authorId;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "article_id")
private Author author;
}
// =====
JPAFactoryQuery query = new JPAQueryFactory(em);
QAuthor a = QAuthor.author;
QBook b = QBook.book;
List<Author> list =
query.selectFrom(a)
.join(a.book, b)
.where(a.id.eq(1))
.fetch();SELECT authors.id AS authors_id,
authors.first_name AS authors_first_name,
authors.last_name AS authors_last_name
FROM authors
WHERE authors.id = 1;SELECT books.id AS books_id,
books.title AS books_title,
books.author_id AS books_author_id
FROM books
WHERE 1 = books.author_id이는 여러 가지 이유로 인해 비효율적입니다.
작가 정보를 전혀 원하지 않았지만, 데이터베이스는 하나의 쿼리가 아니라 두 개의 쿼리를 실행해야 합니다.
또한 책 ID나 작가 ID를 원하지 않았습니다. 물론, 이것은 중요하지 않은 아주 작은 예입니다.
그러나 쿼리가 수백 개의 행을 반환하고 열이 몇 백 개 있다고 상상해 보십시오. 그리고 일부는 LONGBLOB와 같은 다소 큰 콘텐츠로 채워질 수 있습니다.
JPAFactoryQuery query = new JPAQueryFactory(em);
QBook b = QBook.book;
List<Book> list =
query.selectFrom(b)
.where(b.author_id.eq(1))
.fetch();이 예제의 요점은 ORM이 올바른 일을 하는데 어려움을 준다는 것이 아닙니다. 마지막 예는 확실히 이해하기 쉽습니다. 하지만 그들은 또한 미묘한 방법으로 잘못된 쿼리를 쉽게 만들 수 있게 해줍니다. 여러분이 위의 예제를 받았다고 상상해 보세요. 그들은 정확히 작동하고, 유닛 테스트도 형편없이 느리지 않습니다. 당신은 불필요한 복잡성을 확실히 발견할 수 있습니까? 그리고 원하는 질의가 훨씬 더 복잡해질 까요?
Raw SQL 및 Query Builder의 경우, 이와 유사한 복잡한 쿼리를 작성하려면 많은 노력을 기울여야 합니다. 너무 복잡한 질의를 작성하는 것은 어렵고 흔히 있는 일입니다.
The N+1 Problem: Initial Under-Fetching
JPA N+1 문제는 이 포스팅을 확인하면 좋겠다.
https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
N+1 문제 - Incheol's TECH BLOG
Query를 실행하도록 지원해주는 다양한 플러그인이 있다. 대표적으로 Mybatis, QueryDSL, JOOQ, JDBC Template 등이 있을 것이다. 이를 사용하면 로직에 최적화된 쿼리를 구현할 수 있다.
incheol-jung.gitbook.io
'👨🏻💻 Development > 🍃 Spring Boot' 카테고리의 다른 글
| JPA - Attribute Converter (0) | 2021.10.28 |
|---|